BEIJING, China (AIReporter.News): Microsoft Research Asia, a renowned research hub known for pushing the boundaries of technology, has introduced VASA-1, a groundbreaking innovation capable of generating incredibly lifelike talking faces in real-time. With just a single photo and a one-minute audio clip, VASA-1 can produce a wide range of expressive facial nuances and natural head movements, creating a truly immersive and realistic experience. This breakthrough technology holds immense potential for various applications, including virtual avatars, video conferencing, and even the entertainment industry. Microsoft Research Asia is located in Beijing, China, engaging with the academic community to innovate and turn ideas into reality. Microsoft Research Asia is a driving force in technological advancement, playing a pivotal role in shaping the future of AI, computing, and human-computer interaction.
Microsoft introduces VASA-1, an AI model generating lifelike talking face videos by combining audio and images.
Authors: Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong and Baining Guo
Here are the text of report:
Abstract
We introduce VASA, a framework for generating lifelike talking faces with ap- pealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a diffusion-based holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.
Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method delivers high video quality with realistic facial and head dynamics and also supports the online generation of 512 512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors. Project webpage.
Figure 1: Given a single portrait image, a speech audio clip, and optionally a set of other control signals, our approach produces a high-quality lifelike talking face video of 512× 512 resolution
1. Introduction of VASA-1
In the realm of multimedia and communication, the human face is not just a visage but a dynamic canvas, where every subtle movement and expression can articulate emotions, convey unspoken messages, and foster empathetic connections. The emergence of AI-generated talking faces offers a window into a future where technology amplifies the richness of human-human and human-AI interactions. Such technology holds the promise of enriching digital communication [61, 33], increasing accessibility for those with communicative impairments [27, 1], transforming education methods with interactive AI tutoring [7, 29], and providing therapeutic support and social interaction in healthcare [39, 31].
As one step towards achieving such capabilities, our work introduces VASA-1, a new method that can produce audio-generated talking faces with a high level of realism and liveliness. Given a static face image of an arbitrary individual, alongside a speech audio clip from any person, our approach is capable of generating a hyper-realistic talking face video efficiently. This video not only features lip movements that are meticulously synchronized with the audio input but also exhibits a wide range of natural, human-like facial dynamics and head movements.
Creating talking faces from audio has attracted significant attention in recent years with numerous approaches proposed [75, 37, 73, 49, 23, 59, 60, 58, 68, 72, 34, 24]. However, existing techniques are still far from achieving the authenticity of natural talking faces. Current research has predominantly focused on the precision of lip synchronization with promising accuracy obtained [37, 58]. The creation of expressive facial dynamics and the subtle nuances of lifelike facial behavior remain largely neglected. This results in generated faces that seem rigid and unconvincing. Additionally, natural head movements also play a vital role in enhancing the perception of realism. Although recent studies have attempted to simulate realistic head motions [59, 68, 72], there remains a sizable gap between the generated animations and the genuine human movement patterns.
Another important factor is the efficiency of generation, which plays a pivotal role in real-time applications such as live communication. While image and video diffusion techniques have brought remarkable advancements in talking face generation [18, 47, 52] as well as the broader video generation field [5, 8], the substantial computation demands have limited their practicality for interactive systems. A critical need exists for optimized algorithms that can bridge the gap between high-quality video synthesis and the low-latency requirements of real-time applications.
Given the limitations of existing methods, this work develops an efficient yet powerful audio-conditioned generative model that works in the latent space of head and facial movements. Different from prior works, we train a Diffusion Transformer model on the latent space of holistic facial dynamics as well as head movements. We consider all possible facial dynamics – including lip motion, (non-lip) expression, eye gaze and blinking, among others – as a single latent variable and model its probabilistic distribution in a unified manner. By contrast, existing methods often apply separate models for different factors, even with interleaved regressive and generative formulations for them [59, 74, 68, 57, 72]. Our holistic facial dynamics modeling, together with the jointly learned head motion patterns, leads to the generation of a diverse array of lifelike and emotive talking behaviors. Furthermore, we incorporate a set of optional conditioning signals such as main gaze direction, head distance, and emotion offset into the learning process. This makes the generative modeling of complex distribution more tractable and increases the generation controllability.
To achieve our goal, another challenge lies in constructing the latent space for the aforementioned holistic facial dynamics and gathering the data for the diffusion model training. Beyond facial and head movements, a human face image contains other factors such as identity and appearance. In this work, we seek to build a proper latent space for human faces using a large volume of face videos. Our aim is for the face latent space to possess both a total state of disentanglement between facial dynamics and other factors, as well as a high degree of expressiveness to model rich facial appearance details and dynamic nuances. We base our method on the 3D-aided representation [61, 17] and equip it with a collection of carefully-designed loss functions. Trained on face videos in a self-supervised or weakly-supervised manner, our encoder can produce well-disentangled factors including 3D appearance, identity, head pose, and holistic facial dynamics, and the decoder can generate high-quality faces following the given latent codes.
VASA-1 has collectively advanced the realism of lip-audio synchronization, facial dynamics, and head movement to new heights. Coupled with high image generation quality and efficient running speed, we achieved real-time talking faces that are realistic and lifelike. Through detailed evaluations, we show that our method significantly outperforms existing methods. We believe VASA-1 brings us closer to a future where digital AI avatars can engage with us in ways that are as natural and intuitive as interactions with real humans, demonstrating appealing visual affective skills for more dynamic and empathetic information exchange.
*****
2. Related Work
Disentangled face representation learning. The representation of facial images through disentangled variables has been extensively studied by previous works. Some methods utilize sparse keypoints [42, 69] or 3D face models [40, 20, 71] to explicitly characterize facial dynamics and other properties, but these can suffer from issues such as inaccurate reconstructions or limited expressive capabilities.
There are also many works dedicated to learning disentangled representations within a latent space. A common approach involves separating faces into identity and non-identity components, then recombining them across different frames, either in a 2D [10, 74, 32, 67, 35, 57] or 3D context [61, 17]. The main challenge faced by these methods is the effective disentanglement of various factors while still achieving expressive representations of all static and dynamic facial attributes, which is addressed in this work.
Audio-driven talking face generation. Talking face video generation from audio inputs has been a long-standing task in computer vision and graphics. Early works have focused on synthesizing only the lips, achieved by mapping audio signals directly to lip movements while leaving other facial attributes unchanged [51, 11, 37, 67, 12]. More recent efforts have expanded the scope to include a broader array of facial expressions and head movements derived from audio inputs. For instance, the method of [72] separates the generation targets into different categories, including lip-only 3DMM coefficients, eye blinks, and head poses. [68] proposed to decompose lip and non-lip features on the top of the expression latent from [74]. Both [72] and [68] regress lip-related representations directly from audio features and model other attributes in a probabilistic manner. In contrast to these approaches, our method generates comprehensive facial dynamics and head poses from audio along with other control signals. This approach differs from the trend of further disentanglement, seeking instead to create more holistic and integrated outputs.
Video generation. Recent advances in generative models [9, 25, 46, 45] have led to significant progress in video generation. Earlier video generation approaches [56, 53, 44] employed the adversarial learning [22] framework, while more recent methods [66, 6, 21, 30, 3, 8] have leveraged diffusion or auto-regressive models to capture diverse video distributions. Recently, several works concurrent to us [52, 62] have adapted video diffusion techniques to audio-driven talking face generation, achieving promising results despite the slow training and inference speeds. In contrast, our method can deliver both efficiency and high-quality results in the generation of talking face videos.
*****
3. Method
Task definition. As illustrated in Fig. 1, the input to our method consists of a single face image I of an arbitrary identity and a speech audio clip a from, again, an arbitrary person. The goal is to generate a synthesized video of the input face image speaking with the given audio in a realistic and coherent manner. A successfully generated video should exhibit high fidelity in several key aspects: the clarity and authenticity of the image frames, precise synchronization between the audio and lip movements, expressive and emotive facial dynamics, and naturalistic head poses.
Our generation process can also accept a set of optional control signals to guide the generation, which include the main eye gaze direction g, head-to-camera distance d, and emotion offset e. More details will be provided in the later sections.
Overall framework. Instead of generating video frames directly, we generate holistic facial dynamics and head motion in the latent space conditioned on audio and other signals. Given these motion latent codes, our method then produces video frames by a face decoder, which also takes the appearance and identity features extracted using a face encoder from the input image as input.
To achieve this, we start by constructing a face latent space and training the face encoder and decoder. An expressive and disentangled face latent learning framework is crafted and trained on real-life face videos. Then we train a simple yet powerful Diffusion Transformer to model the motion distribution and generate the motion latent codes in the test time given audio and other conditions.
3.1. Expressive and Disentangled Face Latent Space Construction
Given a corpus of unlabeled talking face videos, we aim to build a latent space for human face with high degrees of disentanglement and expressiveness. The disentanglement enables effective generative modeling of the human head and holistic facial behaviors on massive videos, irrespective of the subject identities. It also enables disentangled factor control of the output which is desirable in many applications. Existing methods fall short of either expressiveness [10, 40, 68, 57] or disentanglement [61, 17, 71] or both. The expressiveness of facial appearance and dynamic movements, on the other hand, ensures that the decoder can output high quality videos with rich facial details and the latent generator is able to capture nuanced facial dynamics.
To achieve this, we base our model on the 3D-aided face reenactment framework from [61, 17]. The 3D appearance feature volume can better characterize the appearance details in 3D compared to 2D feature maps. The explicit 3D feature warping is also powerful in modeling 3D head and facial movements. Specifically, we decompose a facial image into a canonical 3D appearance volume Vapp, an identity code zid, a 3D head pose zpose, and a facial dynamics code zdyn. Each of them is extracted from a face image by an independent encoder, except that Vapp is constructed by first extracting a posed 3D volume followed by rigid and non-rigid 3D warping to the canonical volume, as done in [17]. A single decoder takes these latent variables as input and reconstructs the face image, where similar warping fields in the inverse direction are first applied to Vapp to get the posed appearance volume. Readers are referred to [17] for more details of this architecture.
To learn the disentangled latent space, the core idea is to construct image reconstruction loss by swapping latent variables between different images in videos. Our basic loss functions are adapted from [17]. However, we identified the poor disentanglement between facial dynamics and head pose using the original losses. The disentanglement between identity and motions is also imperfect. Therefore, we introduce several additional losses crucial to achieve our goal. For instance, inspired by [35], we add a pairwise head pose and facial dynamics transfer loss to improve their disentanglement. Let Ii and Ij be two frames randomly sampled from the same video of a subject.
We extract their latent variables using the encoders, and transfer Ii’s head pose onto Ij as ˆ Ij,zpose = D(Vapp, zid, zpose, zdyn) and Ij’s facial motion onto Ii as Ii,zdyn = D(Vapp, zid, zpose, zdyn). The discrepancy loss betweenˆIj,zpose and Ii,zdyn is subsequently minimized. To reinforce the disentanglement between identity and motions, we add a face identity similarity loss for the cross-identity pose and facial motion transfer results. Let Is and Id be the video frames of two different subjects, we can transfer the motions of Id onto Is and obtain ˆˆ Is,zpose,zdyn = = D(Vapp, zid, zpose, zdyn). Then, a cosine similarity loss between the deep face identity features [15] extracted from Is and ˆI pose dyn is applied. s,zd ,zd
3.2. Holistic Facial Dynamics Generation with Diffusion Transformer
Given the constructed face latent space and trained encoders, we can extract the facial dynamics and head movements from real-life talking face videos and train a generative model. Crucially, we consider identity-agnostic holistic facial dynamics generation (HFDG), where our learned latent codes represent all facial movements such as lip motion, (non-lip) expression, and eye gaze and blinking. This is in contrast to existing methods that apply separate models for different factors with interleaved regression and generative formulations [59, 74, 68, 57, 72]. Furthermore, previous methods often train on a limited number of identities [72, 65, 19] and cannot model the wide range of motion patterns of different humans, especially given an expressive motion latent space.
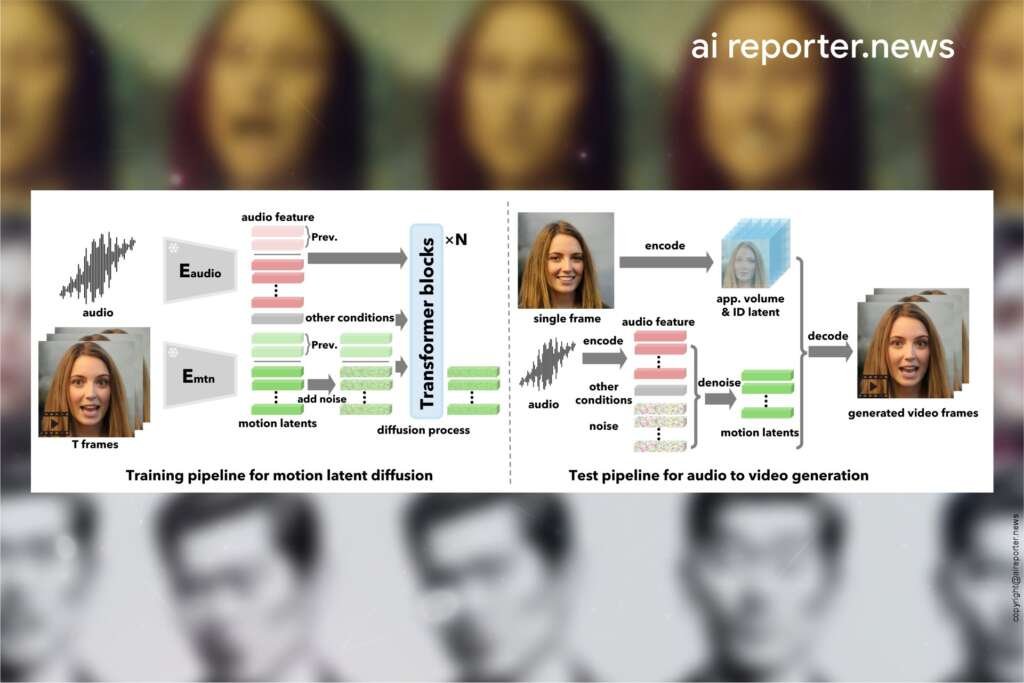
Figure 2: Our holistic facial dynamics and head pose generation framework with diffusion transformer.
In this work, we utilize diffusion models for audio-conditioned HFDG and train on massive talking face videos from a large number of identities. In particular, we apply a transformer architecture [55, 36, 50] for our sequence generation task. Figure 2 shows an overview of our HFDG framework.
Conditioning signals. The primary condition signal for our audio-driven motion generation task is the audio feature sequence A. We also incorporate several additional signals, which not only make the generative modeling more tractable but also increase the generation controllability.
Specifically, we consider the main eye gaze direction g, head-to-camera distance d, and emotion offset e. The main gaze direction, g = (θ, ϕ), is defined by a vector in spherical coordinates. It specifies the focused direction of the generated talking face. We extract g for the training video clips using [70] on each frame followed by a simple histogram-based clustering algorithm. The head distance d is a normalized scalar controlling the distance between the face and the virtual camera, which affects the face scale in the generated face video. We obtain this scale label for the training videos using [16].
The emotion offset e modulates the depicted emotion on the talking face. Note that emotion is often intrinsically linked to and can be largely inferred from audio; hence, e serves only as a global offset added to enhance or moderately alter the emotion when required. It is not designed to achieve a total emotion shift during inference or produce emotions incongruent with the input audio. In practice, we use the averaged emotion coefficients extracted by [41] as our emotion signal.
In order to achieve a seamless transition between adjacent windows, we incorporate the last K frames of the audio feature and generated motions from the previous window as the condition of the current one. To summarize, our input condition can be denoted as C = [Xpre, Apre; A, g, d, e]. Classifier-free guidance (CFG) [26].
During training, we use a drop probability of 0.1 for each condition except for Xpre and Apre for which we use 0.5. This is to ensure the model can well handle the first window with no preceding audio and motions (i.e., set to ). We also randomly drop the last few frames of A to ensure robust motion generation for audio sequences shorter than the window length.
3.3. Talking Face Video Generation
At inference time, given an arbitrary face image and an audio clip, we first extract the 3D appear- ance volume Vapp and identity code zid using our trained face encoders. Then, we extract the audio features, split them into segments of length W , and generate the head and facial motion sequences {X = {[zpose, zdyn]}} one by one in a sliding-window manner using our trained diffusion transformer H. The final video can be generated subsequently using our trained decoder.
*****
4. Experiments
Implementation details. For face latent space learning, we use the public VoxCeleb2 dataset from
[13] which contains talking face videos from about 6K subjects. We reprocess the dataset and discard the clips with multiple individuals and those of low quality using the method of [48]. For motion latent generation, we use an 8-layer transformer encoder with an embedding dim 512 and head number 8 as our diffusion network. The model is trained on VoxCeleb2 [13] and another high-resolution talk video dataset collected by us, which contains about 3.5K subjects. In our default setup, the model uses a forward-facing main gaze condition, an average head distance of all training videos, and an empty emotion offset condition. The CFG parameters are set to λA = 0.5 and λg = 1.0, and 50 sampling steps are used.
Evaluation benchmarks. We evaluate our method using two datasets. The first is a subset of VoxCeleb2 [13]. We randomly selected 46 subjects from the test split of VoxCeleb2 and randomly sampled 10 video clips for each subject, resulting in a total of 460 clips. These video clips are about 5 15 seconds long (80% are less than 10 seconds), with most of the content being interviews and news reports. To further evaluate our method under long speech generation with a wider range of vocal variations, we further collected 32 one-minute clips of 17 individuals. These videos are predominantly sourced from online coaching sessions and educational lectures and the talking styles are considerably more diverse than VoxCeleb2. We refer to this dataset as OneMin-32.
4.1. Qualitative Evaluation
Visual results. Figure 1 presents some representative audio-driven talking face generation results of our method. Visually inspected, our method can generate high-quality video frames with vivid facial emotions. Moreover, it can generate human-like conversational behaviors, including sporadic shifts in eye gaze during speech and contemplation, as well as the natural and variable rhythm of eye blinking, among other nuances. We highly recommend that readers view our video results online to fully perceive the capabilities and output quality of our method.
Generation controllability. Figure 3 shows our generated results under different control signals including main eye gaze, head distance, and emotion offset. It is evident that our generation model can well interpret these signals and produce talking face results that closely adhere to these specified parameters.

Figure 3: Generated talking faces under different control signals. Top row: results under different main gaze direction condition (forward-facing, leftwards, rightwards, and upwards, respectively). Middle row: results under different head distances (from far to near). Bottom row: results under different emotion offset (neutral, happy, angry and surprised, respectively).
Disentanglement of face latents. Figure 4 shows that when applying the same motion latent sequences onto different subjects, our method effectively maintains both the distinct facial movements and the unique facial identities. This indicates the efficacy of our method in disentangling identity and motion. Figure 5 further illustrates the effective disentanglement between head pose and facial dynamics. By holding one aspect constant and changing the other, the resulting images faithfully reflect the intended head and facial motions without interference.
Figure 4: Disentanglement between identity and motion. In these examples, the same generated head
and facial motion sequences are applied onto three different face images.
Out-of-distribution generation. Our method exhibits the capability to handle photo and audio inputs that fall outside the training distribution. For instance, as shown in Figure 6, it can handle artistic photos, singing audio clips (top two rows), and non-English speech (the last row). Notably, these data variants were not present in the training dataset.
4.2. Quantitative Evaluation
Evaluation metrics. We use the following metrics for quantitative evaluation of our generated lip movement, head pose and overall video quality, including a new data-driven audio-pose synchroniza- tion metric trained in a way similar to CLIP [38]:
- Audio-lip synchronization. We use a pretrained audio-lip synchronization network, i.e., Sync- Net [14], to assess the alignment of the input audio with the generated lip movements in videos. Specifically, we compute the confidence score and feature distance as SC and SD respectively. Higher SC and lower SD indicate better audio-lip synchronization quality in general.
Audio-pose alignment. Measuring the alignment between the generated head poses and input audio is not trivial and there are no well-established metrics. A few recent studies [72, 50] employed the Beat Align Score [43] to evaluate audio-pose alignment. However, this metric is not optimal because the concept of a “beat” in the context of natural speech and human head motion is ambiguous. In this work, we introduce a new data-driven metric called Contrastive Audio and Pose Pretraining (CAPP) score. Inspired by CLIP [38], we jointly train a pose sequence encoder and an audio sequence encoder and predict whether the input pose sequence and audio are paired. The audio encoder is initialized from a pretrained Wav2Vec2 network [2] and the pose encoder is a randomly initialized 6-layer transformer network. The input window size is 3 seconds. Our CAPP model is trained on 2K hours of real-life audio and pose sequences, and demonstrates a robust capability to assess the degree of synchronization between audio inputs and generate poses (see Sec. 4.3).
Figure 5: Disentanglement between head pose and facial dynamics. From top to bottom: the raw generated sequence, applying generated poses with fixed initial facial dynamics, and applying generated facial dynamics with fixed initial head pose and pre-defined spinning poses, respectively.
- Pose variation intensity. We further define a pose variation intensity score ∆P which is the average of the pose angle differences between adjacent frames. Averaged over all the frames of all generated videos, ∆P provides an indication of the overall head motion intensity generated by a method.
- Video quality. Following previous video generation works [66, 44], we use the Fréchet Video Distance (FVD) [54] to evaluate the generated video quality. We compute the FVD metric using sequences of 25 consecutive frames.
Compared methods. We compare our method with there existing audio-driven talking face genera- tion methods: MakeItTalk [75], Audio2Head [59, 72], and SadTalker [72]. MakeItTalk [75] employs an LSTM to convert audio into dynamic facial landmarks, then use the landmarks to animate a source image into a video sequence through either image warping or neural network based image translation. Audio2Head [59] uses a motion-aware recurrent network to translate audio into head poses, which, along with the original audio, are used to generate dense motion fields. The motion fields are further applied to the image features and the final output is then generated by a neural network. SadTalker [72] employs a VAE network to generate pose offsets from audio and a regression network to predict lip-only coefficients from audio features. A random variable is used for eye blink generation. This method can generate varied poses and eye blinks from identical audio inputs but only regress a deterministic pattern for other motions such as eyebrow, gaze and facial expressions.
Figure 6: Generation results with out-of-distribution images (non-photorealistic) and audios (singing
audios for the first two rows and non-English speech for the last row). Our method can still generate
high quality videos well-aligned with the audios, although it was not trained on such data variations.
Main results. For each audio input, we generate a single video for deterministic approaches, i.e., MakeItTalk and Audio2Head. For SadTalker [72] and our method, we sample three videos for each audio and average the computed metrics. Since different pose representations are used by these methods, we re-extract the head poses from the generated frames to compute the pose-related metrics (i.e., CAPP and ∆P ). For the FVD metric, we use 2K 25-frame video clips of both the real videos and generated ones. For reference purpose, we also report the evaluated metrics of real videos.
Table 1 and Table 2 present the results on the VoxCeleb2 and OneMin-32 benchmarks. Note that we did not evaluate the FVD on VoxCeleb2 as its video quality is varied and often low. On both benchmarks, our method achieves the best results among all methods on all evaluated metrics.
Table 1: Comparison with previous methods on the VoxCeleb2 benchmark.
| Method | SC ↑ | SD ↓ | CAPP ↑ | ΔP |
|---|---|---|---|---|
| MakeItTalk [75] | 4.176 | 15.513 | -0.051 | 0.210 |
| Audio2Head [59] | 6.172 | 8.470 | 0.246 | 0.260 |
| SadTalker [72] | 5.843 | 8.813 | 0.441 | 0.275 |
| Ours | 8.841 | 6.312 | 0.468 | 0.304 |
| Real video | 7.640 | 7.189 | 0.588 | 0.505 |
- SC ↑: Higher is better
- SD ↓: Lower is better
- CAPP ↑: Higher is better
- ΔP: Difference in performance, higher is better
Table 2: Comparison with previous methods on the OneMin-32 benchmark.
| Method | SC ↑ | SD ↓ | CAPP ↑ | ΔP | FVD25 ↓ |
|---|---|---|---|---|---|
| MakeItTalk [75] | -0.123 | 14.340 | 0.002 | 0.190 | 304.833 |
| Audio2Head [59] | 5.992 | 8.211 | 0.205 | 0.239 | 209.772 |
| SadTalker [72] | 5.501 | 8.850 | 0.383 | 0.252 | 214.507 |
| Ours | 7.957 | 6.635 | 0.465 | 0.316 | 105.884 |
| Real video | 7.192 | 7.254 | 0.559 | 0.405 | 29.245 |
- SC ↑: Higher is better (Synchronization Consistency)
- SD ↓: Lower is better (Synchronization Deviation)
- CAPP ↑: Higher is better (Composite Audio-Visual Performance Parameter)
- ΔP: Difference in performance, higher is better
- FVD25 ↓: Lower is better (Fréchet Video Distance)
In terms of audio-lip synchronization scores (SC and SD), our method outperforms all others by a wide margin. Note that our method yields better scores than real videos, which is due to effect of the audio CFG (see Sec. 4.3). Our generated poses are better aligned with the audios especially on the OneMin-32 benchmark, as reflected by the CAPP scores. The head movements also exhibit the highest intensity according to ∆P , although there’s still a gap to the intensity of real videos.
Our FVD score is significantly lower than others, demonstrating the much higher video quality and realism of our results.
4.3. Analysis and Ablation Study
CAPP metric. We analyze the effectiveness of our proposed CAPP metric in measuring the alignment between audio and head pose.
First, we study its sensitivity to temporal shifting by manually introducing frame offsets to ground-truth audio-pose pairs. We extract 3-second clip segments from the VoxCeleb2 test split, yielding approximately 2.1K audio-pose pairs.
The average CAPP score for these pairs is 0.608, as shown in Table 3. Manual frame shifts lead to a rapid decline in CAPP scores, approaching zero for shifts larger than two frames. This indicates a robust correlation between CAPP scores and audio-head pose alignment.
Table 3: CAPP under frame shifting.
| Frame Shift | 0 | ±1 | ±2 | ±3 | ±4 |
|---|---|---|---|---|---|
| CAPP | 0.608 | 0.462 | 0.206 | 0.069 | 0.082 |
This table shows the Composite Audio-Visual Performance Parameter (CAPP) values across different frame shifts, indicating how the performance varies with temporal misalignment between the audio and video frames.
We further investigate the effect of head movement intensity on CAPP by manually scaling the pose differences between consecutive frames using various factors.
Table 4 shows that altering movement intensity negatively impacts the CAPP scores, demonstrating CAPP can assess the alignment of audio and pose in terms of their intensity. However, this sensitivity to intensity appears less pronounced than that to temporal misalignment.
Table 4: CAPP under pose variation scaling.
| Pose Variation Scale | ×0.2 | ×0.5 | ×1.0 | ×1.5 | ×3.0 |
|---|---|---|---|---|---|
| CAPP | 0.368 | 0.584 | 0.608 | 0.587 | 0.505 |
This table demonstrates how the Composite Audio-Visual Performance Parameter (CAPP) changes with varying degrees of pose scaling, showing the robustness of the system to different levels of pose variations.
CFG scales. The CFG strategy [26] for diffusion models can attain a trade-off between sample quality and diversity. Here we evaluate the choice of the CFG scales for the audio and main gaze conditions (i.e., λA and λg in Eq. 2) in our model.
As shown in Table 5, as we increase the value of λg, the accuracy of gaze control improves. Increasing the audio CFG scale to λA = 0.5 significantly enhances the performance of lip-audio alignment (SC and SD), pose-audio alignment (CAPP), and pose variation intensity (∆P ). With positive audio CFG, the lip-audio alignment scores even surpass those evaluated on real videos (the results without audio CFG, i.e., λA = 0, were slightly worse than or comparable to them). Moreover, the FVD score shows a slight drop which indicates slightly better video quality. Further increasing λA marginally improves lip-audio synchronization and reduces FVD25, but at the cost of slightly degrading audio-pose synchronization and gaze controllability. In addition, observa- tions from the generated videos indicate that a higher λA significantly amplifies mouth movements for strong vocals and causes head pose jitter during rapid speech. For balanced performance and overall generation quality, we set λA = 0.5 and λg = 1.0 as our standard configuration.
We also evaluated the influence of sampling steps on performance. Table 5 illustrates that decreasing the steps from 50 to 10 improves audio-lip and audio-pose alignment while compromising pose variation intensity and overall video quality. This step reduction could accelerate the inference process by a factor of 5 for this latent motion generation module.
Table 5: Ablation study of the audio and main gaze CFG scales as well as the sampling steps. Eg denotes the average angular error of main gaze directions and Es is the average head distance error.
| Configuration | SC ↑ | SD ↓ | CAPP ↑ | ΔP | FVD25 ↓ | Eθg ↓ | Es ↓ |
|---|---|---|---|---|---|---|---|
| λA = 0.0, λg = 0.0 | 7.087 | 7.391 | 0.414 | 0.291 | 117.425 | 5.730 | 0.004 |
| λA = 0.0, λg = 1.0 | 7.134 | 7.345 | 0.421 | 0.290 | 116.547 | 5.329 | 0.004 |
| λA = 0.0, λg = 2.0 | 7.108 | 7.386 | 0.414 | 0.298 | 117.784 | 5.064 | 0.005 |
| λA = 0.5, λg = 1.0 | 7.957 | 6.635 | 0.465 | 0.316 | 105.884 | 5.253 | 0.005 |
| λA = 1.0, λg = 1.0 | 8.218 | 6.437 | 0.474 | 0.342 | 104.886 | 5.333 | 0.005 |
| λA = 2.0, λg = 1.0 | 8.295 | 6.397 | 0.455 | 0.395 | 104.293 | 5.531 | 0.005 |
| λA = 0.5, λg = 1.0 (steps = 10) | 8.293 | 6.363 | 0.523 | 0.243 | 117.060 | 5.469 | 0.006 |
| Real video | 7.192 | 7.254 | 0.559 | 0.405 | 29.244 | – | – |
- SC ↑: Higher is better (Synchronization Consistency)
- SD ↓: Lower is better (Synchronization Deviation)
- CAPP ↑: Higher is better (Composite Audio-Visual Performance Parameter)
- ΔP: Difference in performance, higher is better
- FVD25 ↓: Lower is better (Fréchet Video Distance)
- Eθg ↓: Lower is better (Average angular error of main gaze directions)
- Es ↓: Lower is better (Average head distance error)
This table includes various metrics like synchronization consistency, synchronization deviation, and others to assess the impact of audio and gaze control scaling.
*****
5. Conclusion
In summary, our work presents VASA-1, an audio-driven talking face generation model that stands out for its efficient generation of realistic lip synchronization, vivid facial expressions, and naturalistic head movements from a single image and audio input. It significantly outperforms existing methods in delivering video quality and performance efficiency, demonstrating promising visual affective skills in the generated face videos. The technical cornerstone is an innovative holistic facial dynamics and head movement generation model that works in an expressive and disentangled face latent space.
The advancements made by VASA-1 have the potential to reshape human-human and human-AI inter- actions across various domains, including communication, education, and healthcare. The integration of controllable conditioning signals further enhances the model’s adaptability for personalized user experiences.
Limitations and future work. There are still several limitations with our method. Currently, it processes human regions only up to the torso. Extending to the full upper body could offer additional capabilities. While utilizing 3D latent representations, the absence of a more explicit 3D face model such as [63, 64] may result in artifacts like texture sticking due to the neural rendering. Additionally, our approach does not account for non-rigid elements like hair and clothing, which could be addressed with a stronger video prior. In the future, we also plan to incorporate more diverse talking styles and emotions to improve expressiveness and control.
*****
6. Social Impact and Responsible AI Considerations
Our research focuses on generating audio-driven visual affective skills for virtual AI avatars, aiming for positive applications. It is not intended to create content that is used to mislead or deceive. However, like other related content generation techniques, it could still potentially be misused for impersonating humans. We are opposed to any behavior to create misleading or harmful contents of real persons, and are interested in applying our technique for advancing forgery detection. Currently, the videos generated by this method still contain identifiable artifacts, and the numerical study shows that there’s still a gap to achieve the authenticity of real videos.
While acknowledging the possibility of misuse, it’s imperative to recognize the substantial positive potential of our technique. The benefits – ranging from enhancing educational equity, improving ac- cessibility for individuals with communication challenges, and offering companionship or therapeutic support to those in need – underscore the importance of our research and other related explorations. We are dedicated to developing AI responsibly, with the goal of advancing human well-being.
*****
Contribution statement
Sicheng Xu, Guojun Chen, Yu-Xiao Guo were the core contributors to the implementation, training, and experimentation of various algorithm modules, as well as the data processing and management. Jiaolong Yang initiated the project idea, led the project, designed the overall framework, and pro- vided detailed technical advice to each component. Chong Li, Zhengyu Zang and Yizhong Zhang contributed to enhancing the system quality, conducting evaluations, and demonstrating results. Xin Tong provided technical advice throughout the project and helped with project coordination. Baining Guo offered strategic research direction guidance, scientific advising, and other project supports. Paper written by Jiaolong Yang and Sicheng Xu.
*****
Acknowledgments
We would like to thank our colleagues Zheng Zhang, Zhirong Wu, Shujie Liu, Dong Chen, Xu Tan and others for the valuable discussions and insightful suggestions for our project.
*****
Contributing Authors
Here’s the table you requested, listing the research team members along with their affiliations and email addresses:
| Name | Affiliation | |
|---|---|---|
| Sicheng Xu* | Microsoft Research Asia | sichengxu@microsoft.com |
| Guojun Chen* | Microsoft Research Asia | guoch@microsoft.com |
| Yu-Xiao Guo* | Microsoft Research Asia | yuxgu@microsoft.com |
| Jiaolong Yang*† | Microsoft Research Asia | jiaoyan@microsoft.com |
| Chong Li | Microsoft Research Asia | chol@microsoft.com |
| Zhenyu Zang | Microsoft Research Asia | zhenyuzang@microsoft.com |
| Yizhong Zhang | Microsoft Research Asia | yizzhan@microsoft.com |
| Xin Tong | Microsoft Research Asia | xtong@microsoft.com |
| Baining Guo | Microsoft Research Asia | bainguo@microsoft.com |
The asterisks (*) next to some names indicate equal contribution, and the dagger (†) denotes the corresponding author.
*****
References
[1] https://www.prnewswire.com/news-releases/deepbrain-ai-delivers-ai-avatar-to-empower-people-with-disabilities-302026965.html, 2024. [Online; accessed 8-Apr-2024].
[2] Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33:12449–12460, 2020.
[3] Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, et al. Lumiere: A space-time diffusion model for video generation. arXiv preprint arXiv:2401.12945, 2024.
[4] James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. https://cdn. openai.com/papers/dall-e-3.pdf, 2(3):8, 2023.
[5] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
[6] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023.
[7] Aras Bozkurt, Xiao Junhong, Sarah Lambert, Angelica Pazurek, Helen Crompton, Suzan Koseoglu, Robert Farrow, Melissa Bond, Chrissi Nerantzi, Sarah Honeychurch, et al. Speculative futures on chatgpt and generative artificial intelligence (ai): A collective reflection from the educational landscape. Asian Journal of Distance Education, 18(1):53–130, 2023.
[8] Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024.
[9] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
[10] Egor Burkov, Igor Pasechnik, Artur Grigorev, and Victor Lempitsky. Neural head reenactment with latent pose descriptors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13786–13795, 2020.
[11] Lele Chen, Zhiheng Li, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Lip movements generation at a glance. In European Conference on Computer Vision, pages 520–535, 2018.
[12] Kun Cheng, Xiaodong Cun, Yong Zhang, Menghan Xia, Fei Yin, Mingrui Zhu, Xuan Wang, Jue Wang, and Nannan Wang. Videoretalking: Audio-based lip synchronization for talking head video editing in the wild. In SIGGRAPH Asia 2022, pages 1–9, 2022.
[13] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. Voxceleb2: Deep speaker recognition. arXiv preprint arXiv:1806.05622, 2018.
[14] Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. In Asian Conference on Computer Vision Workshops, pages 251–263. Springer, 2017.
[15] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019.
[16] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
[17] Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Aleksei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. Megaportraits: One-shot megapixel neural head avatars. In Proceedings of the 30th ACM International Conference on Multimedia, pages 2663–2671, 2022.
[18] Chenpeng Du, Qi Chen, Tianyu He, Xu Tan, Xie Chen, Kai Yu, Sheng Zhao, and Jiang Bian. Dae-talker: High fidelity speech-driven talking face generation with diffusion autoencoder. In Proceedings of the ACM International Conference on Multimedia, pages 4281–4289, 2023.
[19] Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. Faceformer: Speech-driven 3d facial animation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18770–18780, 2022.
[20] Yue Gao, Yuan Zhou, JingluWang, Xiao Li, Xiang Ming, and Yan Lu. High-fidelity and freely controllable talking head video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5609–5619, 2023.
[21] Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
[22] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in Neural Information Processing Systems, 27, 2014.
[23] Yudong Guo, Keyu Chen, Sen Liang, Yong-Jin Liu, Hujun Bao, and Juyong Zhang. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In IEEE/CVF International Conference on Computer Vision, pages 5784–5794, 2021.
[24] Tianyu He, Junliang Guo, Runyi Yu, Yuchi Wang, Jialiang Zhu, Kaikai An, Leyi Li, Xu Tan, Chunyu Wang, Han Hu, et al. Gaia: Zero-shot talking avatar generation. In International Conference on Learning Representations, 2024.
[25] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
[26] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
[27] Esperanza Johnson, Ramón Hervás, Carlos Gutiérrez López de la Franca, Tania Mondéjar, Sergio F Ochoa, and Jesús Favela. Assessing empathy and managing emotions through interactions with an affective avatar. Health informatics journal, 24(2):182–193, 2018.
[28] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8110–8119, 2020.
[29] Greg Kessler. Technology and the future of language teaching. Foreign Language Annals, 51(1):205–218, 2018.
[30] Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, et al. Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
[31] Julian Leff, Geoffrey Williams, Mark Huckvale, Maurice Arbuthnot, and Alex P Leff. Avatar therapy for persecutory auditory hallucinations: What is it and how does it work? Psychosis, 6(2):166–176, 2014.
[32] Borong Liang, Yan Pan, Zhizhi Guo, Hang Zhou, Zhibin Hong, Xiaoguang Han, Junyu Han, Jingtuo Liu,
Errui Ding, and Jingdong Wang. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3387–3396,
2022.
[33] Shugao Ma, Tomas Simon, Jason Saragih, Dawei Wang, Yuecheng Li, Fernando De La Torre, and Yaser Sheikh. Pixel codec avatars. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 64–73, 2021.
[34] Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Zhidong Deng, and Xin Yu. Styletalk: One-shot talking head generation with controllable speaking styles. In AAAI Conference on Artificial Intelligence, pages arXiv–2301, 2023.
[35] Youxin Pang, Yong Zhang, Weize Quan, Yanbo Fan, Xiaodong Cun, Ying Shan, and Dong-ming Yan. Dpe: Disentanglement of pose and expression for general video portrait editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 427–436, 2023.
[36] William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023.
[37] KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In ACM International Conference on Multimedia, pages 484–492, 2020.
[38] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish
Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR,
2021.
[39] Imogen C Rehm, Emily Foenander, Klaire Wallace, Jo-Anne M Abbott, Michael Kyrios, and Neil Thomas. What role can avatars play in e-mental health interventions? exploring new models of client–therapist interaction. Frontiers in Psychiatry, 7:186, 2016.
[41] Andrey V Savchenko. Hsemotion: High-speed emotion recognition library. Software Impacts, 14:100433, 2022.
[42] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. In Advances in Neural Information Processing Systems, 2019.
[43] Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2022.
[44] Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3626–3636, 2022.
[45] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
[46] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
[47] Michał Stypułkowski, Konstantinos Vougioukas, Sen He, Maciej Zi˛eba, Stavros Petridis, and Maja Pantic. Diffused heads: Diffusion models beat gans on talking-face generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5091–5100, 2024.
[48] Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3667–3676, 2020.
[49] Yasheng Sun, Hang Zhou, Ziwei Liu, and Hideki Koike. Speech2talking-face: Inferring and driving a face with synchronized audio-visual representation. In International Joint Conference on Artificial Intelligence, volume 2, page 4, 2021.
[50] Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Gaetan Lin, Jenny Sheng, Yu-HuiWen, Minjing Yu, and Yong-jin Liu. Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models. arXiv preprint arXiv:2310.00434, 2023.
[51] Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics, 36(4):1–13, 2017.
[52] Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive-generating expressive portrait videos with audio2video diffusion model under weak conditions. arXiv preprint arXiv:2402.17485, 2024.
[53] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1526–1535, 2018.
[54] Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019.
[55] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
[56] Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics. Advances in Neural Information Processing Systems, 29, 2016.
[57] Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, and Baoyuan Wang. Progressive disentangled representation learning for fine-grained controllable talking head synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17979–17989, 2023.
[58] Jiayu Wang, Kang Zhao, Shiwei Zhang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Lipformer: High-fidelity and generalizable talking face generation with a pre-learned facial codebook. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13844–13853, 2023.
[59] Suzhen Wang, Lincheng Li, Yu Ding, Changjie Fan, and Xin Yu. Audio2head: Audio-driven oneshot talking-head generation with natural head motion. In International Joint Conference on Artificial Intelligence, 2021.
[60] Suzhen Wang, Lincheng Li, Yu Ding, and Xin Yu. One-shot talking face generation from single-speaker audio-visual correlation learning. In AAAI Conference on Artificial Intelligence, volume 36, pages 2531–2539, 2022.
[61] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10039–10049, 2021.
[62] Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694, 2024.
[63] Yue Wu, Yu Deng, Jiaolong Yang, Fangyun Wei, Qifeng Chen, and Xin Tong. Anifacegan: Animatable 3d-aware face image generation for video avatars. Advances in Neural Information Processing Systems, 35:36188–36201, 2022.
[64] Yue Wu, Sicheng Xu, Jianfeng Xiang, Fangyun Wei, Qifeng Chen, Jiaolong Yang, and Xin Tong. Aniportraitgan: Animatable 3d portrait generation from 2d image collections. In SIGGRAPH Asia 2023, pages 14 1–9, 2023.
[65] Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023.
[66] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
[67] Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. In European Conference on Computer Vision, pages 85–101, 2022.
[68] Zhentao Yu, Zixin Yin, Deyu Zhou, Duomin Wang, Finn Wong, and Baoyuan Wang. Talking head generation with probabilistic audio-to-visual diffusion priors. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7645–7655, 2023.
[69] Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, and Victor Lempitsky. Fast bi-layer neural synthesis of one-shot realistic head avatars. In European Conference on Computer Vision, pages 524–540, 2020.
[70] Raimondas Zemblys, Diederick C Niehorster, and Kenneth Holmqvist. gazenet: End-to-end eye-movement event detection with deep neural networks. Behavior research methods, 51:840–864, 2019.
[71] Bowen Zhang, Chenyang Qi, Pan Zhang, Bo Zhang, HsiangTao Wu, Dong Chen, Qifeng Chen, Yong Wang, and Fang Wen. Metaportrait: Identity-preserving talking head generation with fast personalized adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22096–22105, 2023.
[72] Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8652–8661, 2023.
[73] Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3661–3670, 2021.
[74] Hang Zhou, Yasheng Sun,WayneWu, Chen Change Loy, XiaogangWang, and Ziwei Liu. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on computer Vision and Pattern Recognition, pages 4176–4186, 2021.
[75] Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk: speaker-aware talking-head animation. ACM Transactions On Graphics (TOG), 39(6):1–15, 2020.